








































7 HR Data Sets for People Analytics

HR data sets are rare finds. In this article, I will list the 7 best HR data sets available online. In addition to the data set, I will also list the challenges in the data. This can be a potential analysis or something to look out for in the data.
We strongly advocate using data and statistics as a means to an end. In analytics we want to contribute to solving business issues using data and statistics. Analysis and statistics in itself is not an end – unless you want to learn how to use it. That’s what we wrote this article for.
Note. I may occasionally use the word ‘predict’ loosely in this article. Most data sets have cross-sectional, making it impossible to ‘predict’ a dependent variable.
Now that we’ve wrapped up the formalities and disclaimers, let’s start playing with HR data!
1. Absenteeism at work
This enormous HR data set focuses on employee absence. It contains a staggering 8335 rows and 13 columns of data.
The data set contains employee numbers and names, gender, city, job title, department, store location, business unit, division, age, length of service, and the number of hour absent.
This data set is neatly structured. This means that every employee has a single line and that absence is taken as the total annual absent hours per employee.
Potential interesting analyses
This data set is suitable for identifying pockets of absence in the organization. These pockets may require interventions. ‘AbsentHour’ will be used as a dependent variable. In addition, age and length of service may also be associated with absence – but how? This is for you to find out.
The data set can also be used as an exercise set to predict absence using decision trees or linear models.
Challenge
This data set is quite straightforward. It is large but still manageable in software like SPSS or Excel. You may have to code a number of nominal variables into number values before you can do your analysis but on top of that, the data itself doesn’t pose much of a challenge.
Note: The data does need to be cleaned. Everyone under 18 or above 65 may be removed from the data set.
Download
This data set is created by Lyndon Sundmark, writer of Doing HR Analytics – A Practitioner’s Handbook with R Examples, for the purpose of learning to predict absence as an outcome. The data set can be downloaded here (mirror).
Lyndon provides a detailed explanation of how to do this in his book. Alternatively, you can also download his free, two-part description of this case in which he runs both visual (descriptive) analytics in part 1 (using R) before creating a decision tree and running linear regression to predict absence in part 2. The relevant chapter in his book is based on these two articles.

2. (More) Absenteeism at Work
This HR data set focuses on absence at work. The data set contains 740 rows and 21 columns of data.
The data set contains a number of employee IDs. Each row represents a certain quantity of absence – meaning that one employee can have multiple rows.
Information on employees include the number of children, work load, distance from work, transportation expense, education, height, weight, BMI, and absenteeism time in hours. Other information include the season, month of absence, day of absence, and day of the week.
The data set also classifies absence into 21 categories, or reasons of absence. These include different types of illness, congenital malfunctions, and pregnancy. The full list can be found in the download description on Kaggle.
Potential interesting analyses
This data set can help you find predictors of absence. Potential analyses could be to see if there is an association between BMI and absence, as well as season, work load, distance from work and the other factors in the data set.
Challenge
The challenge of this data set is mostly in structuring the data. An individual employee has multiple records. These need to be combined prior to analysis. This data set also enables you to do longitudinal research.
Download
This data set can be found on Kaggle (mirror).
3. Human Resources Data Set
This next data set is literally a set containing five different smaller data sheets. The data set contains a core_datasheet, an HR data set, a production staff data set, a recruiting cost data set, and a salary grid.
The data set has some interesting properties as the sheets are linked. The HRDataset_v9.csv file contains positions, the salary_grid.csv contains the salaries of these positions, and production_staff.csv file contains all the production functions, including their performance score, number of times they asked for help, daily error rate, and 90-day complaints.
The data set was created by Dr. Rich Huebner and Dr. Carla Patalano for their graduate HRM course on HR metrics and analytics.
Challenge
Other challenges include looking for predictors of suboptimal performance of production staff (using the other data sheets). There are multiple dependent variables for suboptimal performance, including performance ratings, daily error rates, and 90-day complaints. By linking this back to the datasets that resemble the more general HRIS information, you can deploy decision trees and linear regression models to predict performance.
Another data sheet is titled recruiting_cost.csv. This contains the spend on different recruitment channels. The HRDataset_v9.csv contains the source of hire and date of hire, allowing you to potentially calculate metrics like sourcing channel effectiveness and average sourcing channel cost.
The data sheet also contains data on active or termination status, allowing you to predict termination as well, and associate it with all the other data contained in the other data sheets.
This may mean that the main challenge is the abundance of information. Start with a specific research question that you come up with and start to answer it using the data – otherwise you’ll get lost in all the data.
Download
The data set can be downloaded on Kaggle (mirror). The codebook for this data set can be found here.
4. IBM HR Analytics Employee Attrition and Performance
This data set is well-known in the People Analytics world. When IBM creates a data set that enables you to practice attrition modeling, you pay attention. The data set has 1470 rows and 35 columns.
The data set contains data like age, gender, job satisfaction, environment satisfaction, education field, job role, income, overtime, percentage salary hike, tenure, training time, years in current role, relationship status, and more.
With these variables, IBM has created a fairly complete overview that contains the data of the average HRIS combined with a full engagement survey. The data set is therefore great to predict turnover, or to simply find differences between the group that stayed or that left.
Challenge
This data set opens up a lot of possible analyses. One of the most interesting might be to find predictors using decision trees or logistic regression. Note, check Pasha Robert’s slide deck on Why You Shouldn’t Use Logistic Regression to Predict Attrition beforehand!
Alternatively, you can use a simpler one-way ANOVA or Chi-squared tests to find differences between the groups who left and stayed in factors like job satisfaction and whether or not they had stock options.
Download
Originally, the data set was published on IBM’s website but has since been removed. The data set is still available on Kaggle (mirror). Note that in the original IBM file there was a second worksheet called Data Definitions. In Kaggle these data definitions have been included in the description of the file.
5. Turnover data set by Edward Babushkin
Edward Babushkin is a Russian people analyst and prolific writer. Through his Russian blog he has built a large community of people analytics practitioners and has become the face of people analytics in the East.
The data set contains information on gender, age, wage type, way of travel, traffic (source of hire), and big five personality!
Challenge
In one of his translated posts he poses the question: Which employee will be most likely to stay the longest, Johnson, Peterson, or Sidorson? In his support article, he than shows how to predict this using survival analysis.
According to Edward, the data set is real – which is exciting! For the rest, the data is pretty straight forward. The only thing to keep an eye on is that some terms got lost in translation from Russian to English. As an example, ‘independ’ translates to a reversed scale of agreeableness, ‘selfcontrol’ is conscientiousness, ‘anxiety’ is neuroticism, and ‘novator’ stands for openness.
Download
You can download the dataset here (mirror) from Edward’s Dropbox. A support article containing an example analysis can be found here.
6. Job classification
Another, one-of-a-kind data set by Lyndon Sundmark can be used for job classification. Job classifications reflect both job families and pay grade related information. This is especially relevant when new jobs are created which need to fit in the existing job structure.
Jobs have a number of distinct features which impact the job’s classification. These include education level, experience, organizational impact, level of supervision, financial budget, and more. Knowing these factors for different jobs enables a job analyst to classify jobs into groups – which are connected to pay scales and benefit packages.
Challenge
Sundmark points out that Linear Discriminant Analysis (LDA) can be used to find combinations of features which characterize a number of classes of objects or events. Using LDA, Sundmark’s job classification data set can be used to classify newly created jobs in the existing job structure, providing guidelines for newly created functions.
In this dataset, there are 66 job specifications covering 11 paygrades. All the factors mentioned above are included, and more.
Download
You can download the data set here. A support article describing how to do the analysis in R, can be found here (mirror).
7. Engagement survey
One of the hardest data sets to come by are engagement surveys. This has a few reasons, the most important being the high level of confidentiality and company-sensitive information in these surveys.
However, there is a data set available for those who want to learn. In our Statistics in HR course we use an engagement data set with 85 individuals who all filled in an engagement survey. The data set contains variables like performance rating, function group, but also innovation behavior, multi-dimensional engagement scores, personal initiative, career management behavior, mobility behavior (i.e. the likelihood of leaving the company), organizational and professional commitment, and more.
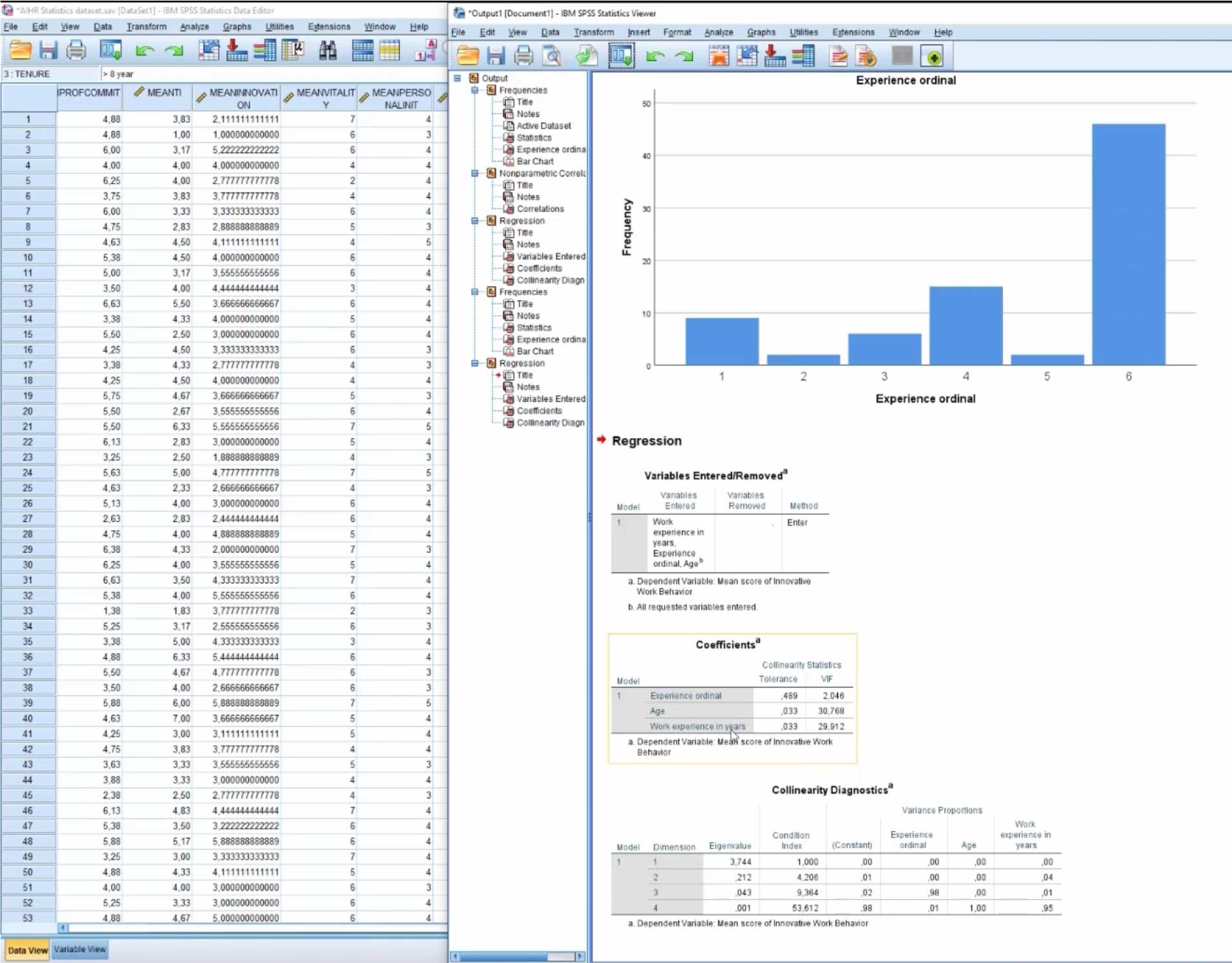
A screenshot from the course with the data set on the left. Data is analyzed in SPSS.
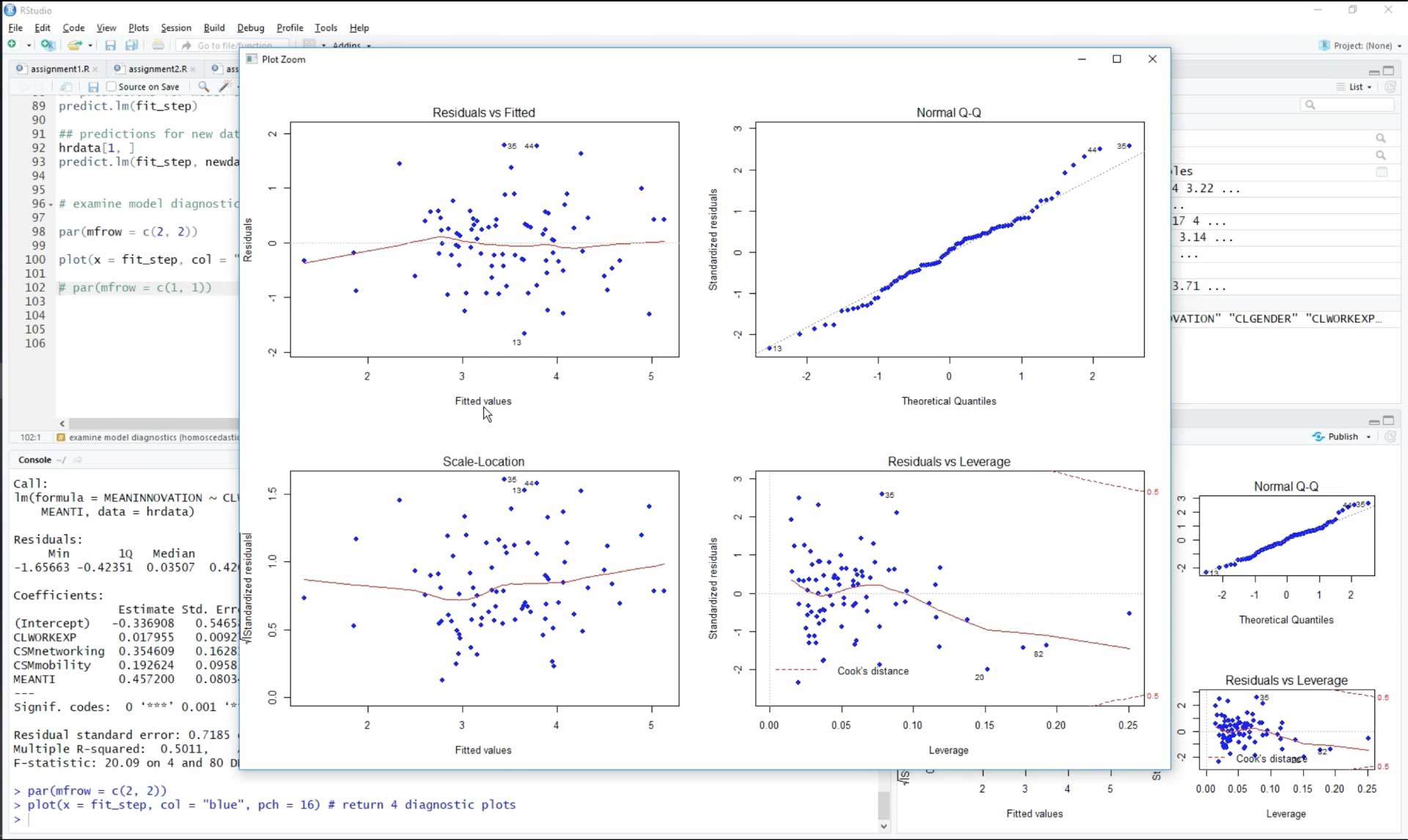
The same data is also analyzed in R. In this fragment, the data is checked for homoscedasticity.
Challenge
The challenge for this data set is straight forward. Students get a data set briefing and codebook with an explanation of the data. The briefing has six questions the students need to answer. This is easier said than done: each answer is a full 30-minute lesson explaining how to run t-tests, ANOVA, multiple linear regression, and so on.
The course teaches you how to run these analyses both in SPSS and in R. Once you’re done with the exercise, there are a number of other challenges that you can solve on your own.
Download
Unfortunately, this data set is not freely available. However, by enrolling for the Statistics in HR course, you get full access to the data and learning material.
Conclusion
The lack of available data is one of the bottlenecks for HR analytics. We hope to partially remove this bottleneck through this article. We also offered you a number of challenges for each of the data sets to make sure you get the most out of it.
A drawback is that only two of these data sets contain real data. The rest is all artificially generated. This can still be of good use for testing out different techniques. However, this data likely has been created to share a practice for a statistical technique or to share a narrative. The real data is doesn’t have that same intention and is therefore more realistic.
This can be fixed by scraping real data from the internet. Jared Valdron started with this, by sharing two scrapers for Meetup.com and WeWork. These can be used for inspiration to generate your own data set.
If you know of any publicly available HR analytics data that we’ve missed, please let us know in the comments. We will update this article accordingly.
Weekly update
Stay up-to-date with the latest news, trends, and resources in HR

Learn more
Related articles






Are you ready for the future of HR?
Learn modern and relevant HR skills, online
